
Introducing Goblin (Part 2)

The last post was starting to get long, so I decided to move the software to its own post.
Goblin was a robot of many firsts. One of them being my first computer-based robot that moved away from the Mini Cheetah software stack. The Mini Cheetah stack worked fine in the past, but it included a lot of bloat and abstraction for things like compatibility with Cheetah 3, running the same controller in sim or on the robot, and numerous computational tools related to MPC.
Rather than porting it to the Jetson, I decided to start from scratch and keep the codebase minimalistic. There are four threads running on the robot to handle critical aspects of control:
IMU thread – samples the IMU at 1 kHz.
SPIne thread – runs at 500 Hz and communicates with the SPIne, sending commands and receiving joint positions, velocities, and torques.
State machine thread – runs at 500 Hz, handling the state machine and all associated tasks. The policy is decimated, with inference running at 50 Hz.
Wireless communication thread – runs at 100 Hz.
Continuing with the theme of firsts, Goblin is my first robot that doesn’t use a classic RC controller. Inspired by the BDX droids, I decided to control the robot using a Steam Deck—the cheapest handheld joystick Linux computer I could find—while also gaining much more software flexibility and the ability to receive real-time feedback.
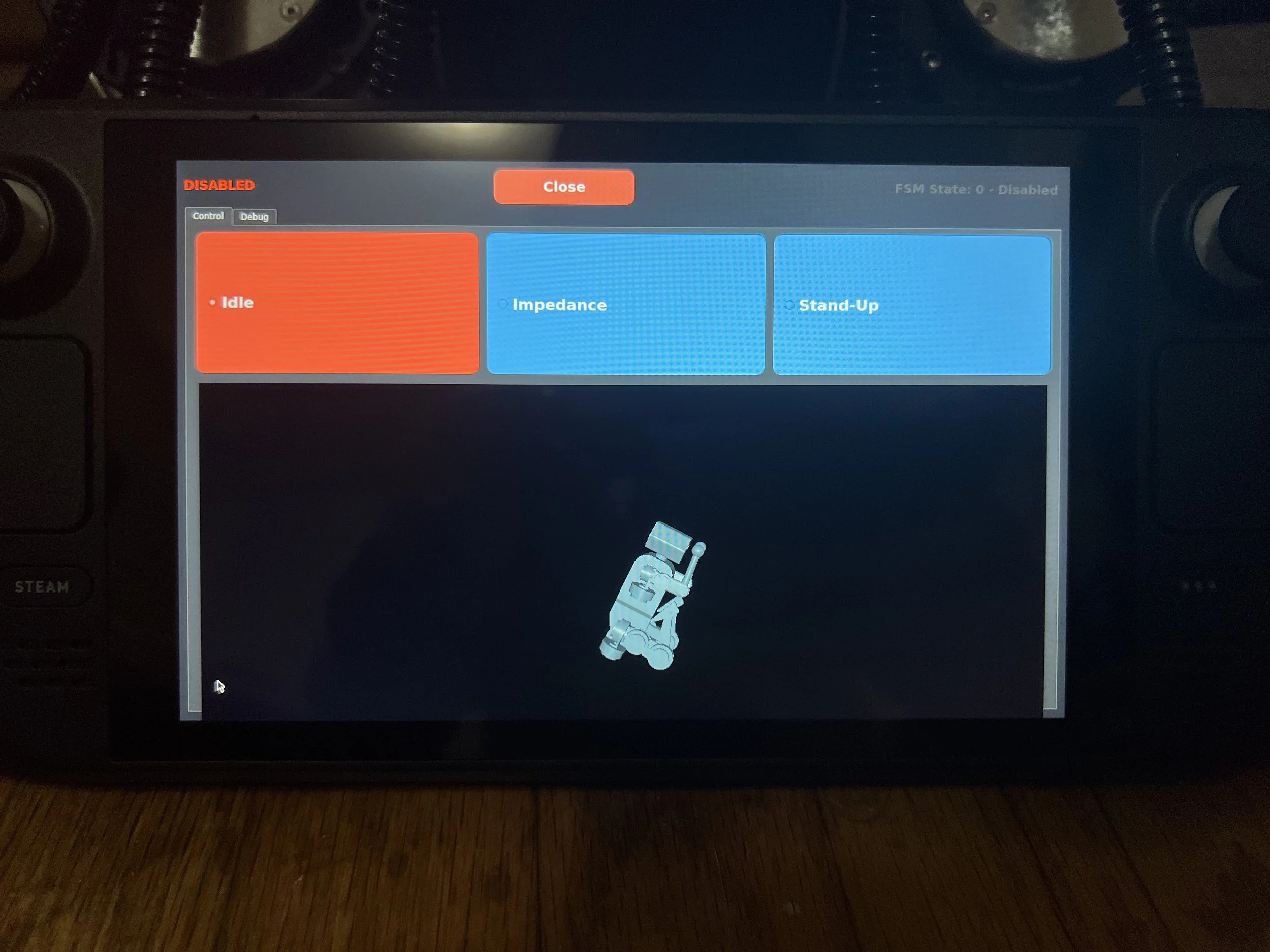
The robot Jetson generates its own Wi-Fi hotspot, which the Steam Deck (or any Wi-Fi-connected device) can join. It uses sockets to exchange data between devices. The controller runs a Python program with a real-time 3D representation of the robot (using Mujoco + joint positions + IMU data), various operation modes, and live plotting of feedback data (accelerometer, gyro, Euler angles, joint positions, velocities, and torques).

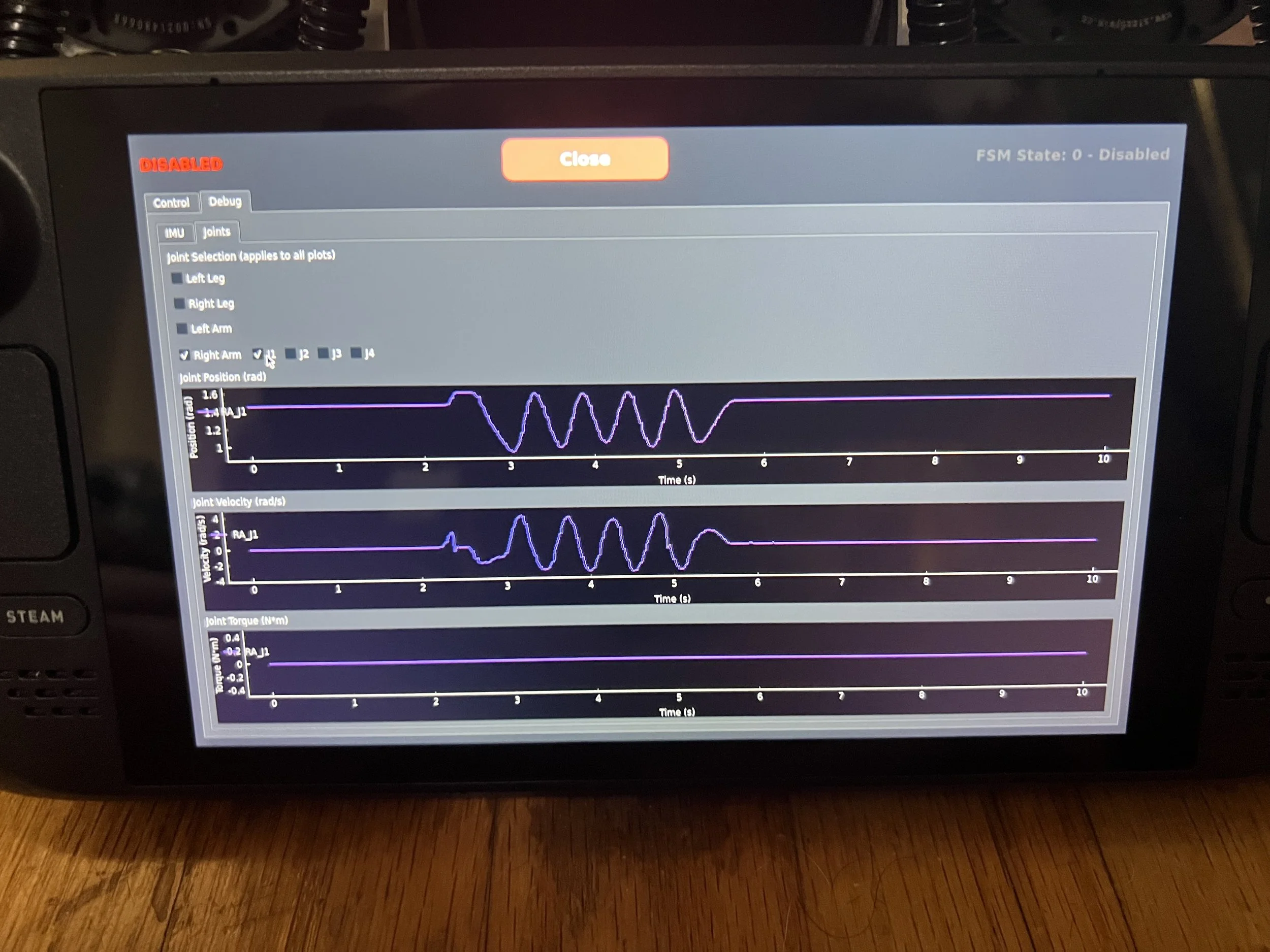
I was very careful to ensure proper failsafing and recovery. The Steam Deck and robot can be started and stopped in any order, communication can recover automatically, and the robot failsafes if it stops receiving data.
Enabling the robot is done by pressing both bumpers simultaneously, and disabling is done by pressing one.
With the infrastructure in place, it was time to generate the policy. I created a simplified model, overriding it with accurate mass and inertia properties. Using Onshape-to-robot, I generated a Mujoco XML and imported it into IsaacSim. One noteworthy step: importing through the GUI didn’t preserve the mass properties from the XML, so I wrote a Python script to handle the import instead—it was far easier than manually editing all the masses and inertias.
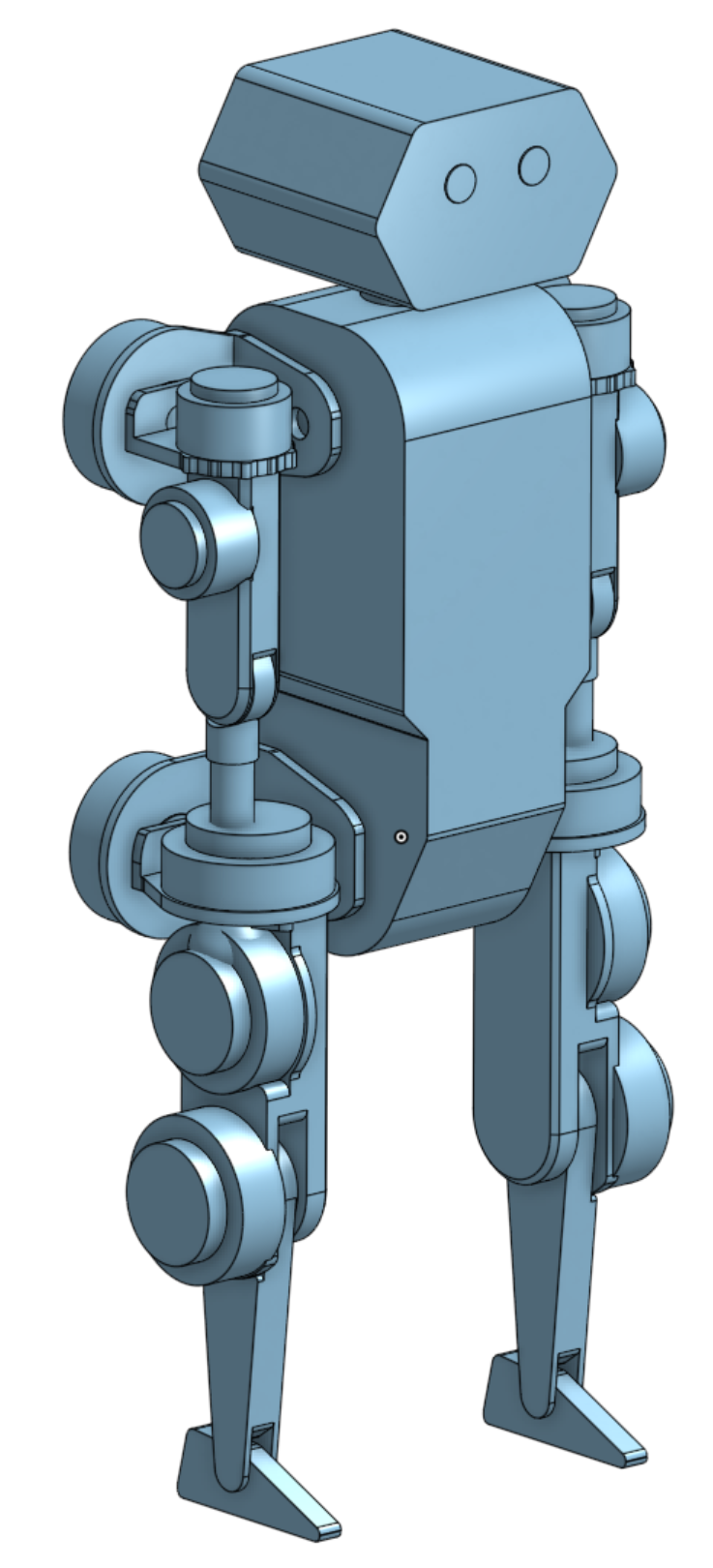
And then came RL. Drawing inspiration from many existing RL environments and tasks, I began training using IsaacLab with RSL_RL.
My observation space included joint positions, joint velocities, projected gravity (from the IMU quaternion), gyro values, and the previous action. The action space consisted of 18 position commands. In some versions of the policy, I added a phase variable to the observation space to encourage specific walking gaits. However, I later removed it because it hurt reactivity—for example, after a push, the robot should step with the most stable foot, not necessarily the “correct” foot based on an arbitrary phase timer.
My workflow was to train the policies, export them as ONNX files, and then run them in Mujoco for Sim2Sim validation. This was especially convenient because both my 3D viewer on the Steam Deck and the Sim2Sim setup were Mujoco-based, making it straightforward to confirm that coordinate systems matched.
To run the policy on the robot, I perform inference in a Python program and use shared memory to interface with the C++ infrastructure code. Inference runs at 50 Hz and is done on the CPU because it’s a small network.
Some anecdotal things I found were: Adding simulated IMU latency made a world of difference for Sim2Real transfer when using the cellphone grade IMU because of the latency of its orientation filter. Adding in more advanced heuristics as rewards seemed to help training develop faster. For example, I added a reward based on a naive Raibert heuristic and the robot learned to initially walk about 50% faster than before, and learned more naturally symmetric walking.
About a month of software later, I had my first policies that could walk, just in time for Open Sauce.

Going forward, my computer has not stopped training new policies and I’m working on better walking. I’ve found that the rewards to encourage not stepping when not needed have been relatively brittle when trying to balance with big steps for normal walking and reacting (if pushed).
It seems like the next direction is to train policies to track animations (to get rid of nebulous reward functions to encourage “correct” behaviors) so perhaps that is something I’ll explore in the future.